
Find and eliminate years of SaaS data exposure
Discover sensitive data hiding across your SaaS applications. AI-powered classification with automated remediation—eliminating years of accumulated PII, PCI, PHI, and secrets in hours.

%201.webp)





%201.webp)
%201.webp)
%201.webp)



Legacy data discovery and classification fail at scale and inundate SecOps with false positives
Discover What Legacy Tools Miss
Legacy DLP tools leave 60-80% of sensitive data undiscovered. Nightfall's AI scans every message, file, and record across years of SaaS history—finding PII in archived Slack channels, secrets in old repos, and PHI in forgotten Google Drive folders.

Eliminate Data Exposure at Petabyte Scaler
Automatically remediate sensitive data across millions of files without manual review. Bulk redact, remove external sharing, or delete with precision—reducing your attack surface by 90%.

Frictionless Deployment
Deploy in minutes via direct API based integrations and a simple but powerful policy experience. No more managing complex on-prem architectures.
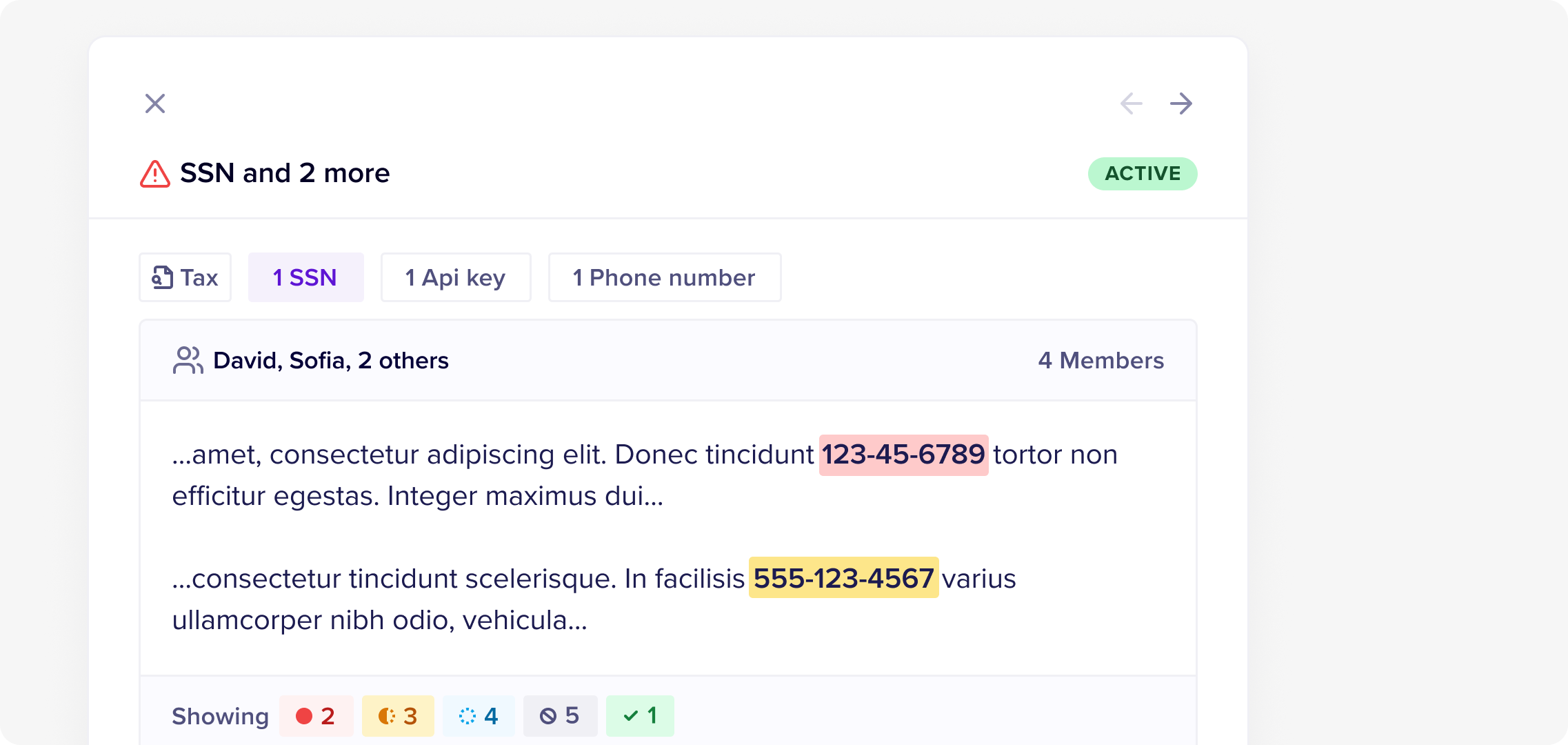
95% Accuracy, Zero Tuning Required
Context-aware AI eliminates false positive noise that cripples legacy tools. Pre-trained models distinguish real SSNs from phone numbers, live API keys from documentation examples - alerts are actionable.

DLP that delivers measurable business outcomes
.webp)
Operational Efficiency
10x more accurate compared to legacy DLP. 10x faster time to remediation due to automation and intuitive UX

Time to Value
Complete deployment across 12+ SaaS apps in an hour vs. industry average of several weeks.

Scale
Automated scanning for petabytes of data with no impact to source applications.
Comprehensive coverage across SaaS applications
Deep discovery across Slack, M365, Google Workspace, GitHub, Salesforce, and many more applications. Scan every file type including images, archives, and code repositories—comprehensive coverage with zero blind spots.
Context-Aware AI Classification
Pre-trained models for PII, PHI, PCI, and secrets detection. Advanced OCR for scanned documents, contextual analysis for business communications, and computer vision for sensitive data in images and screenshots.
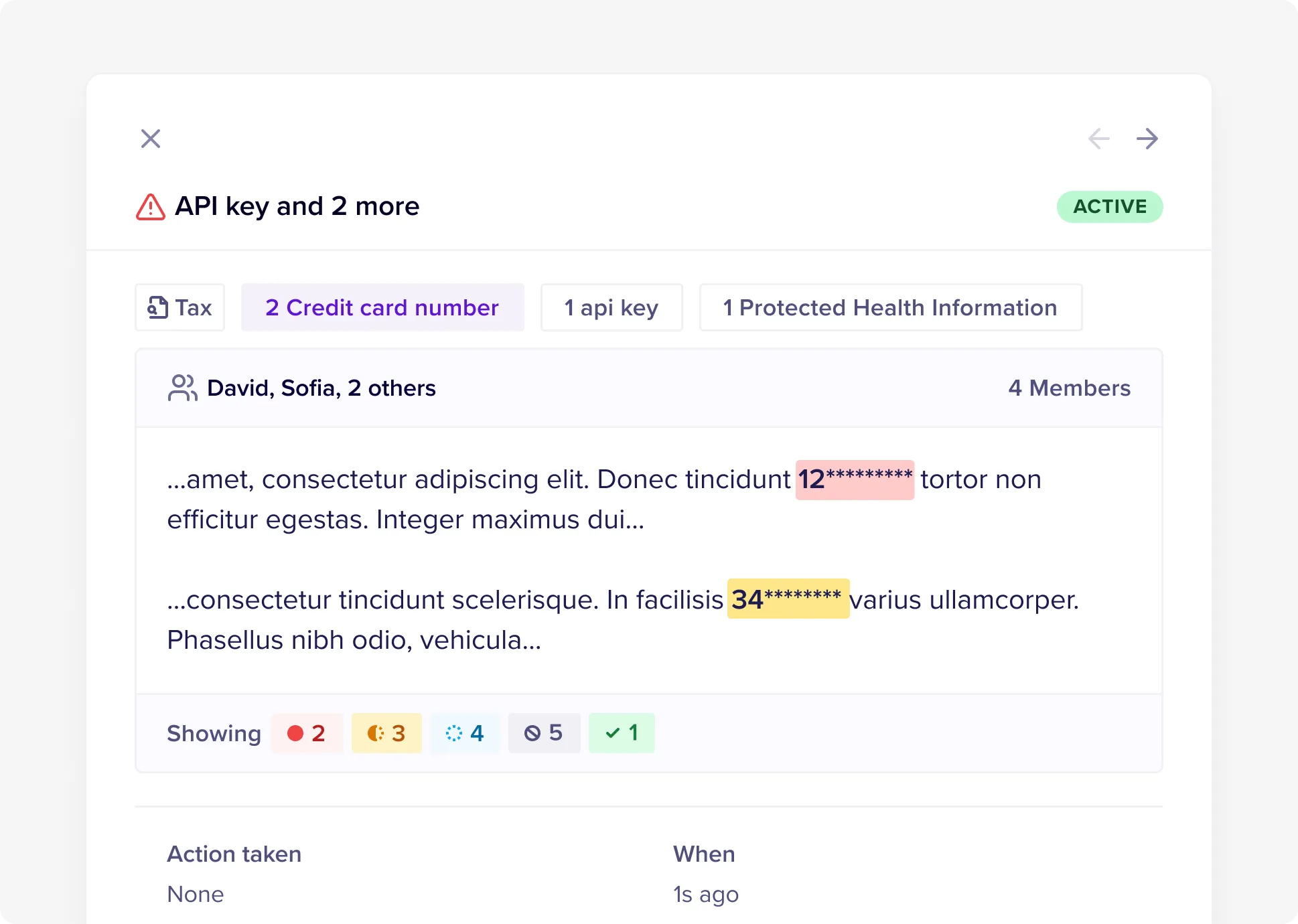
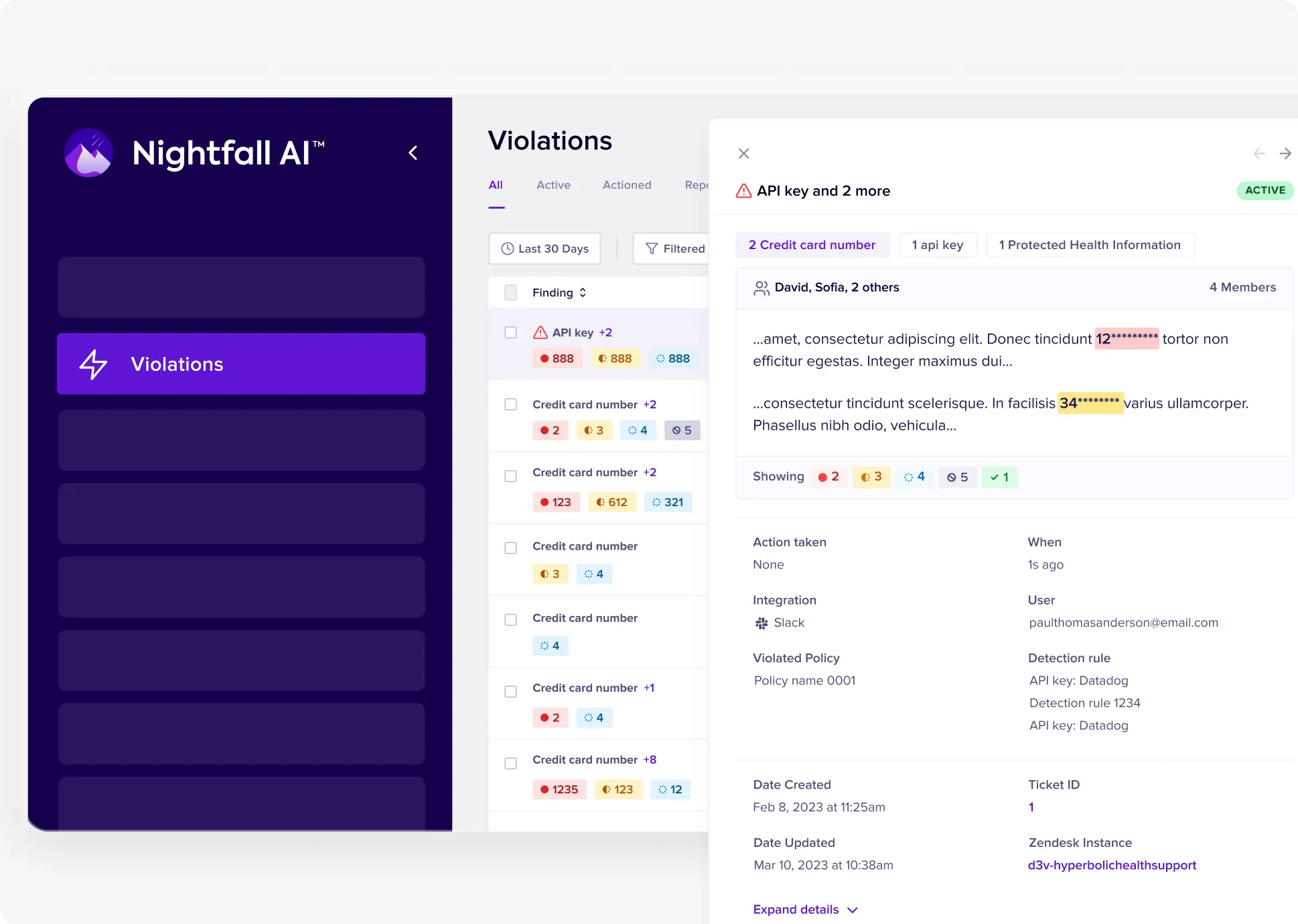
Automated, bulk remediation
Policy-driven bulk actions across thousands of violations. Automatically redact customer data, delete secrets, remove sharing permissions, or classify data - configurable by user, group, or location in each app.
Executive Reporting & Compliance
Real-time dashboards showing data exposure reduction, remediation progress, and compliance posture. Generate audit reports for internal security requirements, PCI DSS, HIPAA or other regulatory requirements.
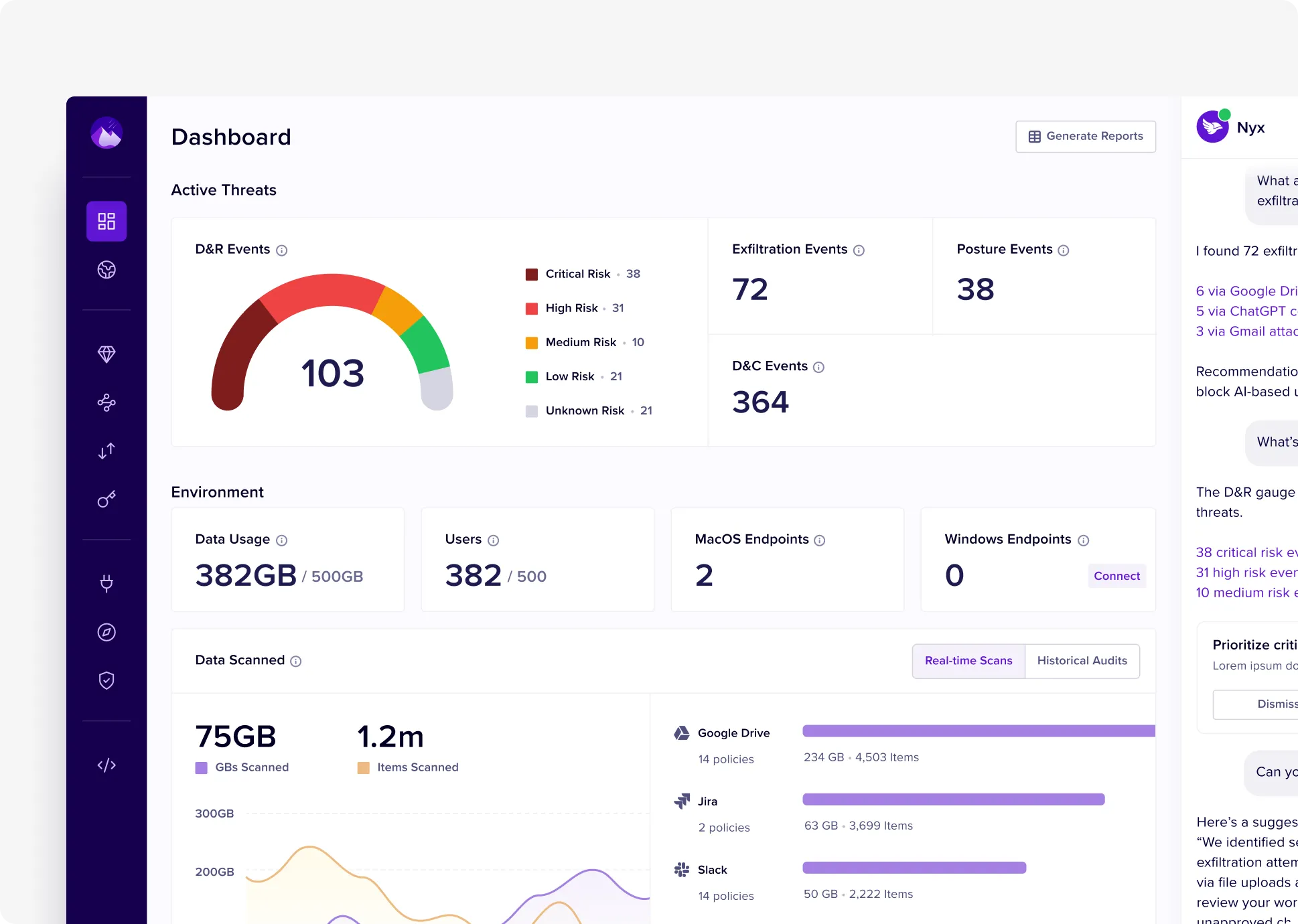

Zero Infrastructure Impact
Pure API integration with no network changes or performance degradation. Scan petabytes of historical data without affecting SaaS application performance or user experience.
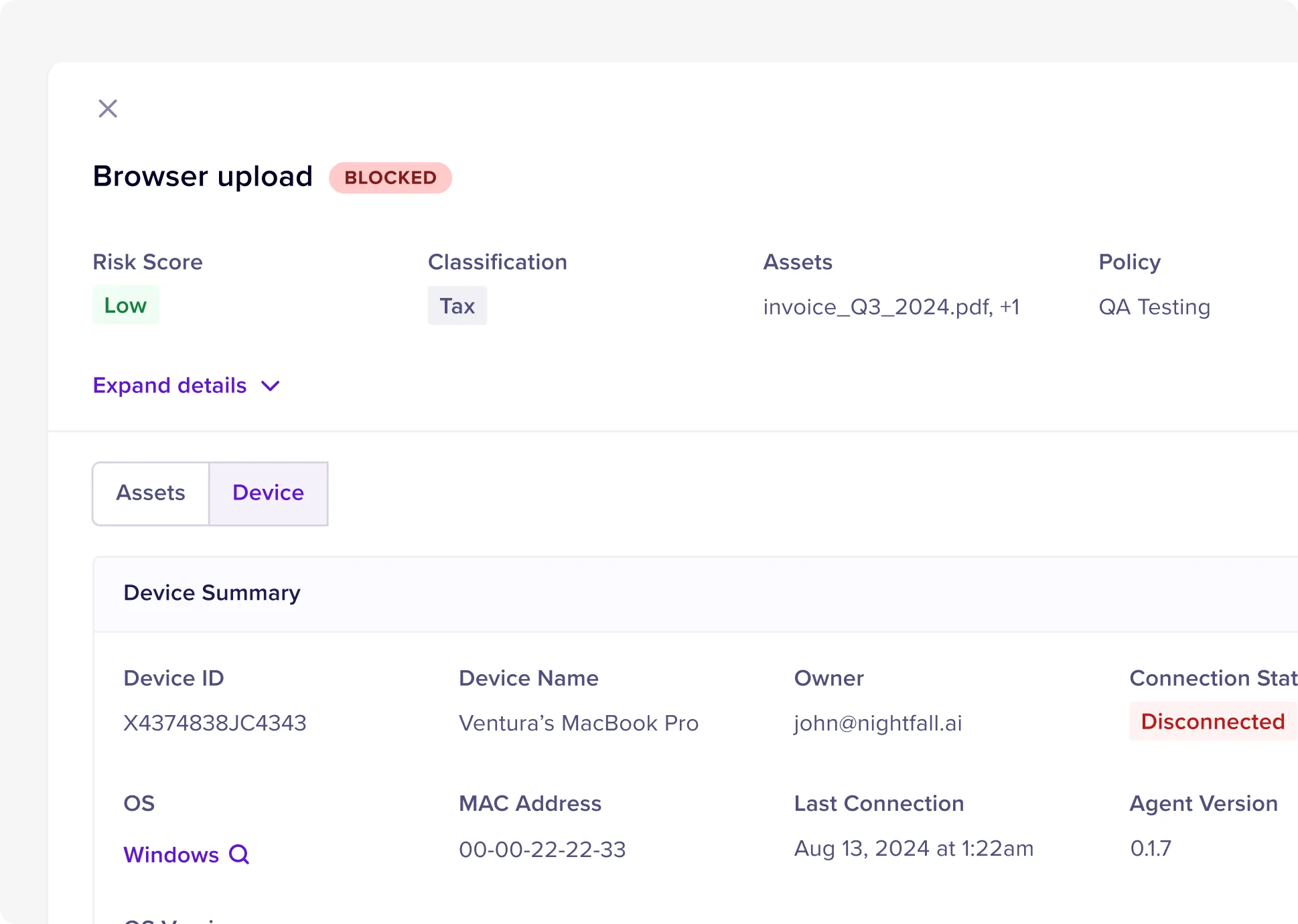
Complete Audit Visibility
Full content preview and remediation tracking for every sensitive data discovery. Detailed logs of what was found, where it was located, and what action was taken.
Case studies
Loved by innovative security teams
95%
precision
10x
lower total cost of ownership
80%
self-resolution


.webp)


Schedule a live demo
Tell us a little about yourself and we'll connect you with a Nightfall expert who can share more about the product and answer any questions you have.
Not yet ready for a demo? Read our latest e-book, Protecting Sensitive Data from Shadow AI.
