.png)
AI Agent Security is quickly becoming one of the most important areas in cybersecurity.
Terms like "agent," "harness," "MCP," "tool calls," "tool responses," "instruction hijacking," "indirect prompt injection," "prompt exfiltration," and "tool misuse" are appearing in conference talks, vendor announcements, podcasts, and industry discussions, often without clear explanations.
At the same time, employees are rapidly adopting tools like Claude Cowork & Code, OpenAI Codex, Microsoft Copilot, and other AI agents that can interact with enterprise systems, applications, and data.
As a result, security teams are facing a new challenge.
The question is no longer just:
"Who is using AI?"
It's increasingly:
"What can that AI access, and what actions can it take?"
This guide introduces the concepts, attack surfaces, and terminology every security leader and practitioner should understand.
Why Agent Security Is Different
Traditional AI security discussions focused primarily on the model.
Today's AI agents are different.
They can:
- Access documents
- Query databases
- Use MCP servers
- Interact with SaaS applications
- Execute workflows
- Take actions on behalf of users
As a result, the attack surface extends far beyond the model itself.
Many of the most important risks now exist in the systems surrounding the model.
AI Agents: Orchestrators and Agent Infrastructure
Two concepts are essential for understanding how AI agents operate in practice: the orchestrator and the agent infrastructure.
The orchestrator — sometimes called the agent runtime — is the software layer that kicks off and manages agent behavior. Examples include Claude Code, Cursor, Windsurf, OpenAI Codex, LangGraph, and CrewAI. The orchestrator is what sequences tasks, decides when to invoke tools, and drives the agent toward a goal.
The agent infrastructure is everything surrounding the model and orchestrator that enables an agent to operate inside an organization:
- Tools
- APIs
- MCP servers
- Permissions
- Data sources
- Memory
- Workflows
- Governance controls
Together, the orchestrator and agent infrastructure transform a standalone language model into an operational AI agent capable of accessing information, interacting with systems, and taking actions on behalf of users.
Both layers create tremendous value — and both expand the attack surface. Agent infrastructure determines:
- What data an agent can access
- What systems an agent can reach
- What actions an agent can perform
- What instructions can influence its behavior
Security teams are increasingly finding that real-world AI risks emerge from these layers rather than from the model itself. As agents become more capable, the key security questions are shifting away from "Can the model be jailbroken?" toward:
- Which orchestrator is managing this agent, and what does it permit?
- Which MCP servers and tools is the agent connected to?
- What sensitive data is flowing through the workflow?
- What actions can the agent perform, and who authorized them?
- How can the orchestrator or infrastructure be manipulated?
Understanding both the orchestrator and the agent infrastructure is foundational to modern AI agent security.
The AI Agent Workflow
A simplified AI agent workflow looks like this:
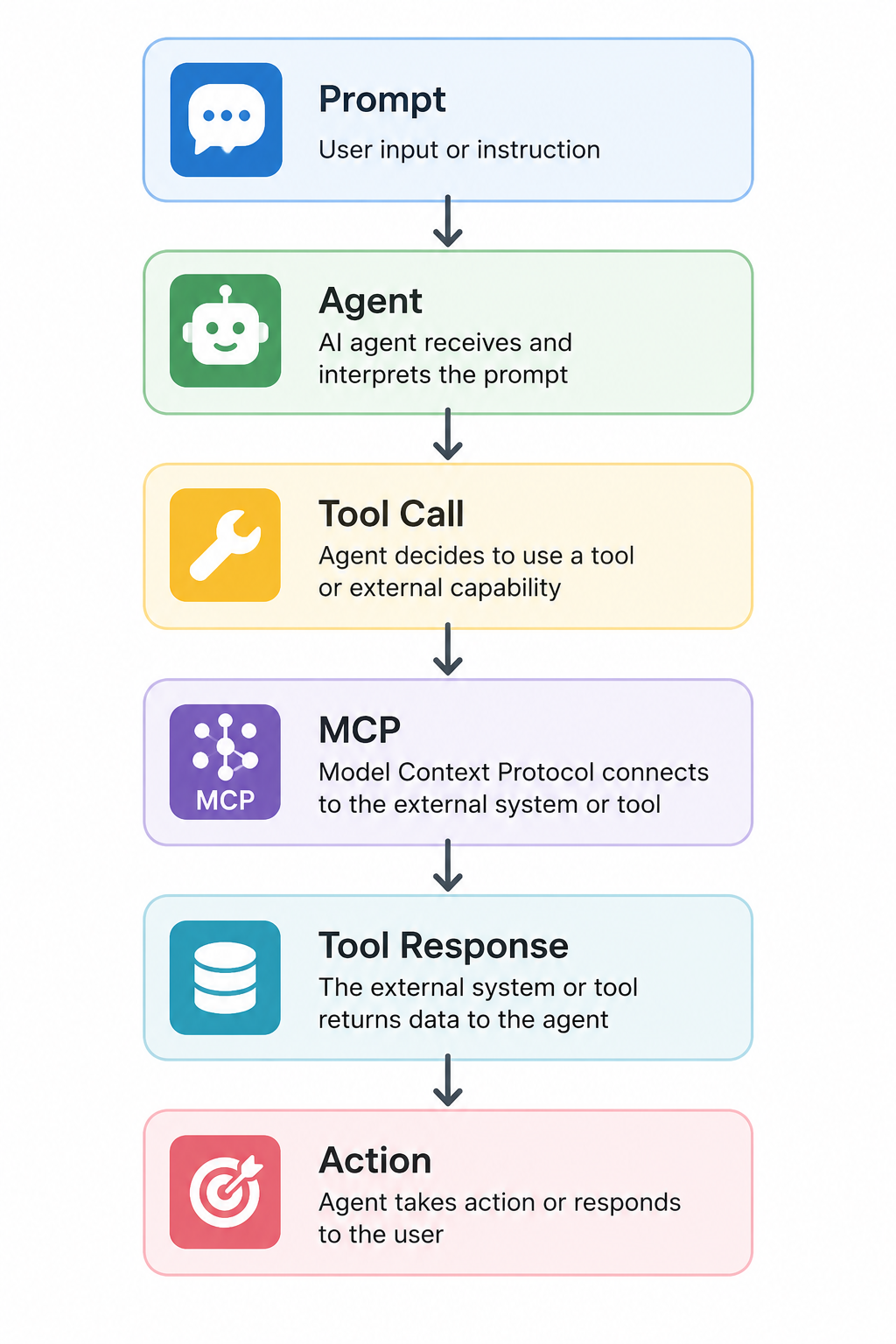
Each step introduces unique security risks.
Understanding where information enters, leaves, and influences the workflow is critical to understanding AI Agent Security.
Hooks
A hook is a point in the AI workflow where security controls, monitoring, or policy enforcement can be applied before an agent processes information, retrieves data, or takes action.
Examples include:
- User Prompt Hooks
- Tool Request Hooks
- Tool Response Hooks
Hooks allow organizations to inspect activity before an agent processes data, takes an action, or consumes external content.
Rather than securing only prompts, modern AI security increasingly relies on controls applied at multiple hooks throughout the workflow.
Attack Surface #1: User Prompts
User prompts are the most familiar attack surface.
Common attacks include:
Instruction Hijacking
Attempts to manipulate an agent's behavior, override instructions, bypass controls, or influence decision-making.
Prompt Injection
A specific form of instruction hijacking that introduces malicious instructions into agent workflows.
Prompt Exfiltration
Attempts to retrieve:
- System prompts
- Hidden instructions
- Internal configurations
- Sensitive contextual information
Attack Surface #2: Tool Requests
Tool requests occur when an agent decides to take action.
Examples include:
- Querying Salesforce
- Accessing Google Drive
- Sending Slack messages
- Creating Jira tickets
Common risks include:
Tool Misuse
Using connected tools in ways that violate policy, expose sensitive data, or perform unintended actions.
Excessive Permissions
Agents possessing broader access than necessary to perform their intended function.
Sensitive Data Exposure
Transferring credentials, customer data, source code, or other sensitive information through AI workflows.
Attack Surface #3: Tool Responses
Tool responses are information returned to an agent by external systems.
Examples include:
- Documents
- Knowledge bases
- Websites
- Database records
- MCP servers
Common risks include:
Indirect Prompt Injection
Malicious instructions embedded in content consumed by the agent.
This makes tool responses one of the most important and frequently overlooked attack surfaces in modern AI systems.
Poisoned Content
Compromised information sources designed to influence agent behavior.
Sensitive Data Leakage
Sensitive information introduced into workflows through retrieved content.
Agent Lifecycle
The agent lifecycle refers to the sequence of interactions that occur as an AI agent receives instructions, accesses tools, retrieves information, and performs actions.
Examples include:
- User prompts
- Tool requests
- Tool responses
- Memory retrieval
- Agent actions
Security controls increasingly need to span the entire lifecycle rather than a single prompt.
MCP (Model Context Protocol)
MCP is an emerging standard that enables AI agents to communicate with external tools and systems.
Think of MCP as a common interface between agents and enterprise resources.
As MCP adoption accelerates, organizations gain flexibility—but also expand the number of systems accessible to AI agents.
Memory
Memory refers to information retained by an AI agent across interactions.
Memory can improve user experience and task completion, but it also introduces new security considerations, including sensitive data retention, memory poisoning, and unauthorized access to historical context.
Agent Observability
One of the biggest challenges facing security teams today is visibility.
Many organizations cannot answer:
- Which agents are running?
- Which MCP servers are being used?
- Which tools are being called?
- What data is flowing through those interactions?
Agent observability refers to the ability to understand:
- What AI agents are doing
- What tools they are using
- What systems they are accessing
- What data is moving through workflows
You can't secure what you can't see.
Agent Telemetry
Agent telemetry is the operational data generated by AI systems.
Examples include:
- User prompts
- Tool requests
- Tool responses
- MCP interactions
- Execution events
OpenTelemetry (OTEL) is an open standard for collecting operational telemetry from software systems. It is increasingly being adopted to capture AI agent activity, tool usage, workflow execution, and other security-relevant events.
Agent telemetry provides the foundation for visibility, monitoring, and security controls.
AI Activity Discovery
Before organizations can secure AI workflows, they must first discover them.
AI Activity Discovery is the process of identifying:
- AI agents
- MCP servers
- Tool calls
- Agent workflows
- AI-driven data flows
Many organizations are discovering that AI has become the next evolution of Shadow AI—not because more employees are using AI, but because AI systems are increasingly capable of taking actions on their behalf.
Skills
Skills are reusable instructions, workflows, or capabilities that can be invoked by an AI agent.
Because skills become part of an agent's operating context, compromised or malicious skills can become a persistent source of instruction hijacking, data exfiltration, or tool misuse.
For example, an employee could download a poisoned skill that appears useful but contains hidden instructions to send sensitive data, credentials, prompts, or tool outputs to a third party.
This makes skills an emerging supply chain risk for AI agents: they are not just productivity add-ons; they can become persistent execution context that influences how an agent behaves.
Tool Descriptions
Tool descriptions are metadata that explain how and when a tool should be used by an AI agent.
Because agents rely on these descriptions when selecting and interacting with tools, compromised or malicious tool descriptions may influence agent behavior and decision-making.
Agent Security vs. Model Security
Model Security focuses on:
- Alignment
- Safety
- Refusal behavior
- Jailbreak resistance
Agent Security focuses on:
- Tool access
- Permissions
- Data exposure
- Instruction hijacking
- Prompt exfiltration
- Tool misuse
- Governance controls
Both are important.
However, as agents become more capable, security teams are increasingly spending more time securing the harness around the model than the model itself.
The Emerging Security Question
For years, organizations asked:
"Who is using AI?"
As AI agents become connected to enterprise systems, a more important question is emerging:
"What can that AI access, and what actions can it take?"
Understanding the workflow, hooks, attack surfaces, and terminology behind AI Agent Security is the first step toward answering that question.
The future of AI security is not just about securing models.
It's about understanding how AI agents interact with data, tools, systems, and users—and securing the harness that connects them all.
Learn more about how to secure MCP and AI agents with Nightfall with a demo.

.svg)
.svg)


